Pratili ste nevolje kompanije Garmin: ruski hakeri uspeli su da im podmetnu ransomware koji je kriptovao podatke i onesposobio sve servise na gotovo nedelju dana. Najzad je Garmin morao da plate ucenu od (priča se) 10 miliona dolara da bi se sve vratilo u normalu. Zar firma te veličine ne pravi backup? Učimo se na njihovim greškama, jer su i naši podaci podložni napadima i havarijama...
Pomisliti da kompanija kao što je Garmin, čija je trenutna kapitalizacija oko 20 milijardi dolara i koja zapošljava 13.000 ljudi širom sveta, nema ozbiljno IT odeljenje sposobno da napravi tako običnu stvar kao što je backup zvuči jeretički, ali su događaji pokazali da je tako. Jer, da su imali upotrebljiv backup, teško da bi na svoju reputaciju stavili takvu mrlju kao što je plaćanje ucenjivaču. Da, svakako su pravili backup, ali cinična poslovica kaže da se firme dele na one koje nemaju backup i one koje misle da imaju backup...
Podaci i backup – nikad zajedno
Slična nevolja snašla je i Javno komunalno preduzeće „Informatika“ iz Novog Sada, kome su hakeri 1. marta ove godine blokirali sve podatke, između ostalog i o računima izdatim građanima kao i uplatama od strane građana. Traženo je 50 bitkoina ili oko 400.000 evra da se podaci otključaju, a pošto Novi Sad nije želeo da plati ucenu (gest koji u svakom slučaju podržavamo!), ostalo im je da prekucavaju podatke sa papirnih izveštaja. Posle toga je nastupila epidemija pa se o ovom problemu nije mnogo govorilo, ali svakako je to bila velika nevolja koja i do sada ostavlja neke tragove.
Ključni problem u oba slučaja bio je u tome što su aktivni računari imali pristup diskovima na kojima se pravi backup, dakle onaj ko „osvoji“ neki server u mreži može da zaključa ne samo osnovne podatke, nego i njihovu kopiju. Korisnik ostaje sa dve jednako beskorisne gomile bajtova, a originalne podatke nema nigde – backup je u pravom smislu te reči imaginaran.
Ispravan (ili makar ispravniji) način za organizovanje backup-a opisali smo u tekstu „Nezvani gost u Redakciji“ iz PC#265 – kada nas je ransomware pogodio, izgubili smo jedan dan dok smo reinstalirali server i vratili podatke sa backup-a, i to je bila sva šteta. Preporučujemo da pročitate taj tekst, a ovde ćemo samo ukratko reći da računari koji prave backup treba da imaju pristup diskovima sa podacima, ali računari koji obrađuju podatke nikako ne smeju imati pristup diskovima na kojima je backup. Dakle, kopiranje podataka na bezbedno mesto ne obavlja računar koji te podatke obrađuje, već drugi računar (ili NAS) koji je zadužen za backup. Da bi takav protokol funkcionisao, treba rešiti problem sa bazama koje su stalno otvorene pa se ne mogu tek tako prekopirati, ali svaki data base sistem (Microsoft SQL Server, Oracle, MySQL...) ima mehanizam kojim se baza stavlja u režim za backup, a nove transakcije se posebno beleže da bi, kada backup bude završen, bile ugrađene u samu bazu.
Dodajmo da ni ovakav scenario nije dovoljno bezbedan – on ne štiti od nesreće koja bi fizički uništila čitav hardver (zemljotres, požar...), kao ni od nekih sistemskih greški koje bi ipak dopustile da se prodre u backup sistem tako što se i on hakuje. Zato je neophodno da se backup povremeno (u slučaju važnih podataka dnevno ili češće) kopira na još jedan set medija koji se isključuju iz mreže i nose na drugu, sigurnu lokaciju, pa deponuju u tamošnji sef. Važni podaci se mogu arhivirati i preko Interneta prenositi na servere koji se nalaze u drugoj državi ili čak na drugom kontinentu.
Serveri kao kućni ljubimci... ili kao stado
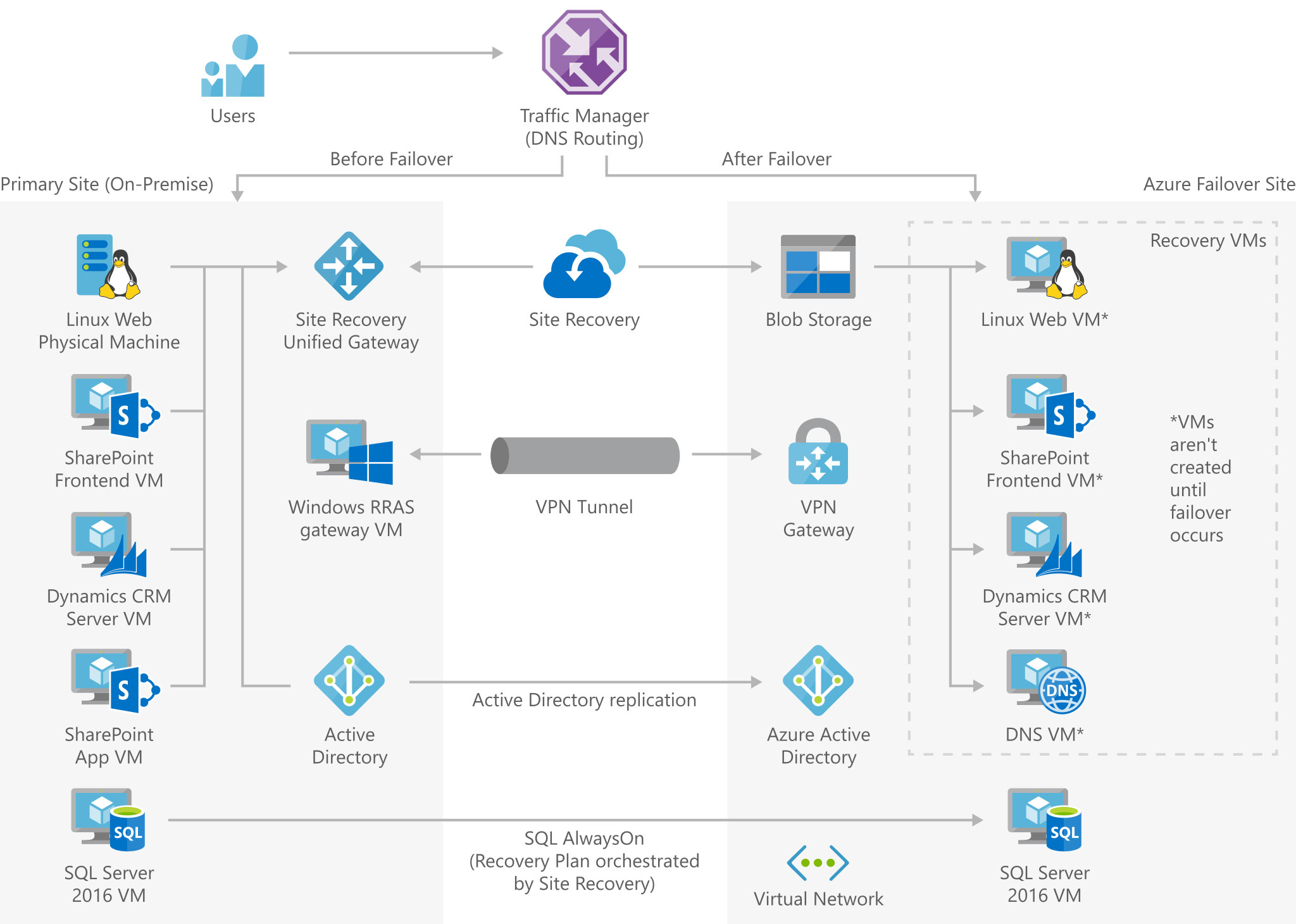
Šematski prikaz enterprise arhitekture, gde se Azure infrastruktura koristi kao failover sistem na koji obrada prelazi u slučaju kraha produkcionog sistema
Opisana procedura je smislena u kućnoj kancelariji ili manjoj firmi gde su podaci jedino što treba sačuvati. Kada nas je pogodio ransomware, prosto smo formatirali disk, ponovo instalirali Windows Server, kreirali korisnike (ovoga puta sa jačim lozinkama) vratili podatke i nesmetano nastavili posao. Ali šta bi bilo da smo, što je svakako Garmin-ov slučaj, poslovanje zasnovali na stotinama servera širom sveta, na kojima su instalirani razni servisi koji međusobno komuniciraju? Super, podaci su sačuvani, ali kako je sav korišćeni softver instaliran i konfigurisan, kako su podešena prava, šta je u kom aktivnom direktorijumu, kako se pristupa podacima u oblaku... Teško da tu može da se krene od instaliranja softvera na svakom od servera, pa da se sačeka update (koji često traje duže od instalacije), pa da se onda stvari polako podešavaju i testiraju... trajalo bi mesecima.
Zanimljiva izreka, koja se (doduše u nešto drugačijem kontekstu) pripisuje Bilu Bejkeru (Bill Baker) iz Microsoft-a, kaže da servere treba tretirati kao stado, a ne kao kućne ljubimce (treat servers as cattle, not pets). Ako administrator treba posebno da konfiguriše neki server i da se njime bavi, on ga tretira kao „kućnog ljubimca“, što znači da pokretanje tog servera zahteva mnogo više vremena i ljudskog rada nego što je neophodno, a podložnije je i greškama jer nije lako zapamtiti karakteristične potrebe svakog „ljubimca“. Osnovna konfiguracija svih servera treba da bude što sličnija, a softver koji se instalira i servisi koji se pokreću da budu zabeleženi u skriptove koji automatizuju proceduru. Kada server treba zameniti, zbog kvara, napada malicioznog softvera, prelaska na jaču hardversku konfiguraciju ili bilo kog drugog razloga, uzme se novi računar, pokrene skript i sve automatski dolazi u željeno stanje, a server je posle te automatizovane procedure spreman da se uključi u mrežu praktično bez čovekove intervencije.
Sve ovo je lako reći, a nije preteško ni realizovati pošto svi serverski operativni sistemi omogućavaju kreiranje automatskih instalacionih procedura (u Linux svetu se za upravljanje konfiguracijama često koristi alat Ansible, dok je Microsoft je od toga napravio čitavu nauku), ali zahteva kasniju disciplinu – kada se u konfiguraciju servera unesu neke izmene, treba ih ugraditi i u skriptove za automatsku instalaciju servisa. Važne su i povremene probe koje će pokazati da li skript i dalje automatski kreira adekvatno konfigurisan server. Obično se takve probe vrše na virtuelnim mašinama, da bi se smanjili zahtevi za fizičkim hardverom, a samim tim i troškovi.
Sistem otporan na otkaze
Kao što se nikada ne može napisati (netrivijalni) softver koji je potpuno lišen bagova ili konfigurisati računar tako da bude potpuno otporan na napade zlonamernih hakera, tako se ne može napraviti ni sistem potpuno otporan na otkaze. To ne znači da je trud uložen u kreiranje sigurnog sistema uzaludan – stvar je kompromisa koliko ćete rada, znanja i novca uložiti u otpornost sistema. Što više uložite, bićete bezbedniji i lakše ćete se oporaviti posle eventualne havarije ili napada.
Počnimo od nekih osnovnih smernica. Pre svega, ne smete imati ni jedan servis koji se izvršava na samo jednom računaru – bilo kakva havarija tog računara bi onesposobila servis, a havarije nisu retke. Zato se servis mora obezbediti na dva ili više nezavisnih sistema, tako da ako je jedan od njih onesposobljen, ostali preuzimaju posao, možda sa malo slabijim performansama, ali bez ispadanja. U nekom jednostavnom slučaju mogu, recimo, da se kreiraju dva e-mail servera, mail1.firma.rs i mail2.firma.rs, pa da se svi zahtevi koji stižu na mail.firma.rs distribuiraju tako da jedan ide na mail1, sledeći na mail2 i tako u krug. Ako mail2 nije raspoloživ, sav posao će privremeno obavljati mail1.
To lepo zvuči kod servisa koji obrađuju neke konekcije, ali podatke ne možete tek tako držati na dva računara – ubrzo bi informacije bile nekonzistentne. Na Linux platformi se u tu svrhu često koristi Distributed Replicated Block Device (DRBD) mehanizam koji, na nivou kernela, sinhronizuje podatke smeštene na više servera. Možete to pojednostavljeno zamisliti kao neki RAID, samo što se ne radi o više diskova u jednom kompjuteru, nego o više kompjutera u istom klasteru. Ako se koristi Windows Server okruženje, treba proučiti Windows Server Failover Clustering mehanizme.
Backup kao servis
Duplirani ili utrostručeni podaci nikako ne znače da je problem backup-a rešen. Da, zaštitili smo se od kvara nekog računara, ali ako se ransomware zapati na glavnom sistemu, sve te kopije će biti kriptovane. Zato u pozadini treba imati još jedan set servera koji povremeno kopiraju podatke sa produkcionog sistema, ali to neće biti NAS koji samo skladišti podatke, već sistem jednak produkcionom.
Ukoliko osnovni serveri „padnu“, backup serveri se mogu odmah proglasiti za glavne servere, ali bez mogućnosti upisa izmena (izmene bi trebalo skladištiti negde drugde), dok se ne shvati kako su glavni serveri kompromitovani i zatim oni vratili u funkciju. U zavisnosti od frekvencije kopiranja podataka, backup serveri nemaju baš ažurno stanje svega, što će predstavljati problem, ali će barem sistem brzo biti reaktiviran.
Među procedure za backup sistema treba uključiti i redovnu kontrolu ispravnosti napravljenog backup-a. Jedini način da budete sigurni da je to što imate relevantna kopija jeste da pokušate vraćanje svega na sistem za testiranje backup-a. On treba da testira funkcionalnosti rezultujućeg sistema, i da proveri konzistentnost podataka.
Probni restore je dobra prilika da se proceni koliko je vremena potrebno za vraćanje podataka, kako biste imali predstavu o tome koliko će sistem biti nedostupan u slučaju realne havarije. Na osnovu toga možete da napravite koliko-toliko precizan plan za tu potencijalno komplikovanu proceduru.
Ako se u otpornost sistema uloži više para, moguća su i pouzdanija rešenja u kojima su svi uneseni podaci read-only tj. ne mogu se menjati, nego se izmene beleže kao dalje (opet read-only) transakcije, pa se do ažurnog stanja dolazi primenom svih transakcija na osnovni podatak. Ako je budžet još veći, read-only promene bi se replicirale kroz niz data centara. Mnogo zavisi i od prirode podataka, koliko se oni često menjaju i koliko im se često pristupa.
U oblaku je sigurnije?
Sigurnost podataka je jedan od važnih aduta za prelazak u cloud. Gledano iz ugla pojedinačnog korisnika ili manje firme, podaci u nekom OneDrive, Dropbox ili Google Drive skladištu su veoma sigurni. Treba proveriti šta vaša pretplata podržava, ali ako plaćate bilo šta, sva je prilika da se čuvaju ne samo tekuće datoteke, nego i njihove prethodne verzije, možda i pola godine unazad. Ako ransomware šifruje vaše podatke, biće samim tim šifrovani i podaci u cloud-u, ali ćete se lako vratiti na prethodnu, ispravnu verziju koja je nedostupna zlonamernom softveru koji se zapatio na vašem računaru.
A ako neko hakuje infrastrukturu koju koriste Microsoft, Google ili Dropbox? To deluje kao prilično neverovatan događaj, ali zašto biste neograničeno verovali u bilo čiju kompetentnost? Neki korisnici su napravili skriptove koji, recimo, backup-uju podatke sa OneDrive-a na Dropbox, ali nama se najviše sviđa da podatke imamo kod sebe. Ako se koristi bilo koji sync tool, kopija (original?) je po prirodi stvari na lokalnom disku, ali povremeno treba praviti i kopiju na hard-disk koji nije stalno uključen, već se bezbedno krije u nekoj fioci ili sefu.
Ako koristite cloud za ozbiljnije stvari nego što je skladištenje podataka, dakle ako tamo imate virtuelne servere ili čitavu infrastrukturu, stvari postaju komplikovanije. Ne možete očekivati da će neko rešiti sve vaše probleme, ali vam itekako može pomoći prilikom njihovog rešavanja. Ukoliko koristite Azure infrastrukturu, treba da automatizujete konfigurisanje Azure resursa (Infrastructure as Code, IaC), što vam daje mogućnost da od razvojnog okruženja po potrebi brzo napravite test okruženje, a od test okruženja produkciono okruženje. Dobar link za početak pretrage bezbednosnih tema je Azure Disaster Recovery servis, azure.microsoft.com/en-us/solutions/backup-and-disaster-recovery/.
Vaši podaci i vaš ICT infrastruktura su sigurni onoliko koliko želite, to jest koliko ste spremni da platite. Račun može da se plaća pre nego što nastupe problemi ili, što je Garmin iskusio, kada se katastrofa već desila. U drugom slučaju račun je mnogo veći, ne samo u novcu već i u reputaciji firme, pa i njenom tržišnom uspehu. Najvažnije je učiniti da bezbednost bude proces, a ne niz jednokratnih akcija – ako vas čitanje ovog teksta navede da napravite backup, to je svakako dobro, ali ne znači previše. Potrebno je da napravite sistem koji će učiniti da se podaci redovno i automatski čuvaju, a da ispad bilo kog segmenta infrastrukture ne onesposobi čitavu firmu na duže vreme. Posle toga možete da razmišljate o balansu između cene i efikasnosti oporavka od IT katastrofe.