 | | (kliknite za veću sliku) |
Ako se bavite naukom ili ste makar gledali treći film o Indijana Džonsu, znate da sva istraživanja počinju u biblioteci. Doduše, biblioteke nisu ono što su bile: nekada ste papirnu knjigu mogli da konzervirate, a danas se informacije objavljuju na televiziji i Web sajtovima gde ih iz minuta u minut i iz dana u dan zamenjuju nove vesti. Stari i „nepotrebni“ podaci se na bolje organizovanim sajtovima odlažu u arhive koje se mogu pretraživati, dok se na većini mesta staro naprosto briše. Ako je istraživaču potreban podatak koji je nekada postojao negde na Web-u, imaće velikih problema da ga nađe ili će čak morati da odustane od potrage.
Četvrta dimenzija
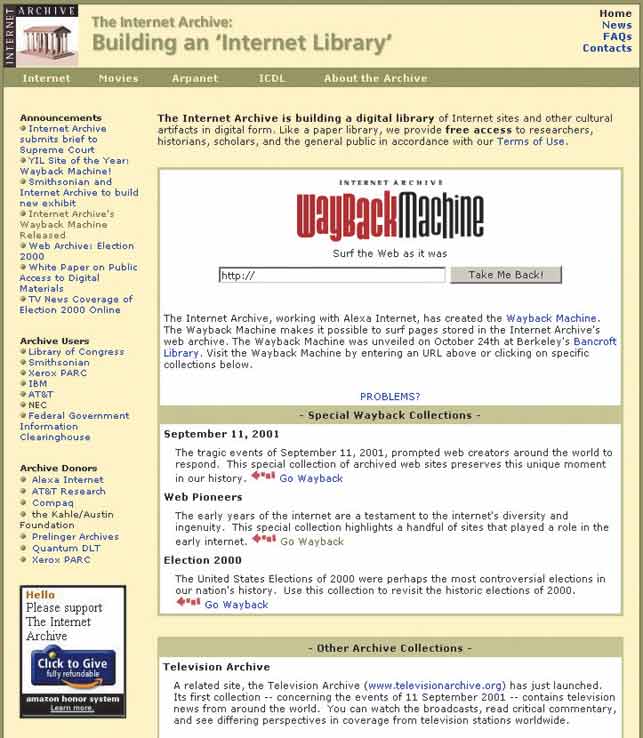
„Četvrtu dimenziju“ Web-a pokušavaju da osvoje tvorci popularnog servisa Alexa (www.alexa.com  ), u saradnji sa firmama AT&T, Compaq i Xerox – još krajem 1996. godine njihovi „Internet roboti“ počeli su da pretražuju Web i memorišu stanje sajtova. Za pet godina sakupljeno je neverovatnih 100 terabajta podataka koji su stavljeni na uvid javnosti kroz Internet Archive Wayback Machine na adresi www.archive.org . ), u saradnji sa firmama AT&T, Compaq i Xerox – još krajem 1996. godine njihovi „Internet roboti“ počeli su da pretražuju Web i memorišu stanje sajtova. Za pet godina sakupljeno je neverovatnih 100 terabajta podataka koji su stavljeni na uvid javnosti kroz Internet Archive Wayback Machine na adresi www.archive.org .
 |
Upotreba servisa je veoma jednostavna – unesete URL i dobijete spisak datuma kada je ta stranica arhivirana, od 1996/97. godine do danas. Kliknete na neki od tih linkova i pred vama se nađe izgled sajta od pre nekoliko godina; linkovi na tom sajtu i dalje funkcionišu, pa možete surfovati po bivšoj prezentaciji. Izbor arhiviranih sajtova je veoma širok (ambicija je da se arhivira „čitav Internet“), pa smo našli gomilu YU prezentacija i njihov nostalgični izgled iz 1997, 1998. i kasnijih godina. Sve to je moguće zahvaljujući farmi od nekoliko stotina HP-ovih servera, pri čemu svaki od njih ima po 512 MB memorije i 300 GB diskove. Sistem radi pod FreeBSD-om i Linux-om i predstavlja dobru reklamu za besplatne operativne sisteme.
Treba, ipak, znati da je www.archive.org pre sajt za (sjajnu!) zabavu nego alatka za ozbiljna istraživanja. Glavni problem nije u greškama pri memorisanju stranica (često fale neke sličice ili tasteri, što je posebno primetno na domaćim sajtovima, pošto Web crawler nije imao „strpljenja“ za naše spore linkove); najzad, i knjige u bibliotekama su često oštećene. „Otisci Interneta“ nažalost nisu uzimani sistematično, pa je sa sajtova koji su dnevno ažurirani memorisan tek delić objavljenih informacija. Osim toga, nisu obezbeđeni alati za „dubinsko“ pretraživanje starih informacija; trebalo bi napraviti nekakav hibrid arhive i Google-a, ali je teško i pretpostaviti kakvi bi računarski resursi za to bili potrebni. Dok čekamo neko sveobuhvatnije rešenje, Internet Archive Wayback Machine pokazuje kako će izgledati globalna biblioteka XXI veka.
|