 | Slika 1: Automatsko čitanje ručno pisanog teksta pomoću neuronske mreže
(kliknite za veću sliku) |
Tokom prethodna dva meseca upoznali smo se sa strukturom i principom rada neuronskih mreža, a na primeru lociranja registarske tablice vozila i čitanja registarske oznake, videli smo kako to sve izgleda u praksi. Neuronske mreže ne rade algoritamski nego empirijski, ne baratajući sa sigurnim podacima i sigurnim rezultatima. Prilikom prepoznavanja svakog oblika (u ovom slučaju znaka ili cifre) izlazni podatak je tablica verovatnoće za svaki od mogućih rezultata. Ako, recimo, treba prepoznati cifru (u primeru iz prošlog broja časopisa to je bila cifra 6), na izlazu iz mreže dobićemo tablicu faktora podudaranja za svaku od mogućih cifara. Taj faktor će, na primer, za cifru 6 biti 0,79, za cifru 8 biće 0,43 i tako dalje. Najmanje podudaranja biće sa ciframa koje imaju iz osnova različitu vizuelnu strukturu, kao što je u našem slučaju bila cifra 7, čiji je faktor podudaranja u našem primeru bio samo 0,02.
Program će, naravno, odabrati „prvoplasiranog“ iz ove tabele, ali neće zanemariti ni ostale. U najjednostavnijem slučaju, ostale rezultate će iskoristiti da proceni uspešnost prepoznavanja znaka, jer što je manja razlika između prvog i drugog, to je veća i mogućnost da je prepoznavanje bilo pogrešno. Napredniji programi za optičko prepoznavanje znakova (OCR) će rezultat prepoznavanja svake reči porediti sa rečnikom pa će se, u slučaju nepoklapanja jednog znaka sa nekom od legitimnih reči (pri čemu se koriste „magloviti“, fuzzy algoritmi) vratiti na verovatnoće ostalih znakova i možda usvojiti neki koji je po verovatnoći nešto niži od „pobedničkog“, ako se bolje poklapa s nekom od reči iz rečnka, ili ako se ta reč već ponavlja u tekstu.
Teško je dati globalnu procenu pogrešivosti neuronske mreže. Kod prepoznavanja teksta, uspešnost u velikoj meri zavisi od kvaliteta skeniranog teksta, rezolucije skeniranja, dobre topologije projektovane neuronske mreže, kao i kvaliteta i dužine treninga za odgovarajući font. Ne treba zanemariti ni prilagođenost fonta optičkom prepoznavanju – serifni fontovi, kod kojih često dolazi do incidentnog spajanja znakova prilikom štampe ili skeniranja, otežavaju separaciju slova, pa su i greške češće. Zato se u poslednje vreme pojavljuju fontovi koji već u svom nazivu imaju prefiks OCR i koji su dobro prilagođeni automatskom čitanju.
Najgori je ishod prepoznavanja ručno pisanog teksta. Ovde važi prosto pravilo da ako čovek može lako da pročita takav tekst, i neuronska mreža će biti uspešna, sa oko 5% do 15% grešaka. Za štampani tekst uspešnost je znatno viša, jer će se broj grešaka u najčešće kretati između 0,1% i 1%. Kod nekih dobro odštampanih OCR tekstova, grešaka skoro i da nema.
Registarske tablice
 | | Slika 2: Jedan od odbačenih predloga za font novih registarskih oznaka |
Problem sa tablicama je u tome što ne možemo da ih skinemo sa vozila i stavimo na skener, nego raspolažemo snimkom načinjenim iz daljine, u potpuno nekontrolisanim svetlosnim uslovima. Da stvar bude još gora, tablice su često prljave, što povećava mogućnost greške. Ostaje nam samo još jedan parametar koji utiče na tačnost prepoznavanja i na koji, srećom, možemo da utičemo – font. Zato su mnoge evropske zemlje angažovale stručnjake koji su projektovali specijalne fontove koji se pouzdano prepoznaju korišćenjem neuronskih mreža. Rezultate tog ozbiljnog rada vidimo na tablicama stranih automobila.
Veliki broj država se u ovome poslužilo iskustvom Nemačke, jer su njeni stručnjaci dizajnirali font koji možda ne izgleda dopadljivo, ali sadrži tri važne osobine. Prva je da se ovakve oznake veoma teško menjaju eventualnim docrtavanjem crnih linija ili prebrisavanjem belim korektorom. Recimo, slovo F nikako ne možete da pretvorite u E, kao ni slovo P u R ili broj 6 u 8. Ove prepravke bi bile lako uočljive, a mogla bi da ih locira i neuronska mreža.
Druga važna osobina je da se oznake lako čitaju golim okom, sa minimalnom mogućnošću pogrešnog čitanja iz daljine. Treća je da se sa maksimalnom pouzdanošću prepoznaju u neuronskoj mreži. Sve ove osobine su na neki način međusobno povezane. Ako su linije na sličnim znacima različito prostorno i stilski organizovane, dobićemo font koji je možda estetski nedosledan, ali će prepravka biti praktično nemoguća, a ljudsko i mašinsko čitanje biće pouzdanije.
A kod nas?
I mi smo praktično dokazali tezu da su tri nabrojane osobine tesno povezane: odabrali smo font kod koga je lako izvesti zloupotrebu prepravkom, a uz to se teško i nepouzdano čita, ne samo ljudskim okom nego i elektronskim sistemom. Na slici 2 je font koji je kod nas najpre predstavljen kao kandidat za nove registarske tablice. To je nemački FE‑Schrift font, modifikovan utoliko što su uklonjeni strani karakteri a dodati Č, Ć, Ž i Š, koji se sastoje od standardnih karaktera sa dijakriticima ("kukicama" iznad C, Z i S). Ovi dijakritici su nesrazmerno veliki, ali je to neophodno da bi čitanje bilo bez greške.
A onda je odlučeno da se ipak primeni „naš“ font, minimalno izmenjen u odnosu na onaj koji smo do sada koristili. Da nevolja bude veća, dijakritici su „zalepljeni“ za slova i do te mere smanjeni, da je čak i čoveku teško da ih uoči, osim iz neposredne blizine. Nije ništa bolja situacija ni na slovu Đ, kod koga je crtica prekratka, pa i tu treba očekivati puno grešaka čak i kod čitanja golim okom, a naročito kod sistema za automatsko čitanje.
 |
Kako bi se povećao broj mogućih kombinacija, zadržana su i slova X, Y i W. Ovo ne mora da bude samo po sebi loše, ali je W nevešto dizajnirano, jer se, pri postojećem odnosu debljine linije i širine znaka, vizuelno sve stapa u veliku crnu mrlju, naročito ako se čita iz daljine. Znaci su prilično upadljivo razmaknuti, što je svakako dobro za optičko prepoznavanje, mada verovatno nije bilo potrebno toliko ih razmicati. Taj prostor bi bio znatno bolje iskorišćen da su znaci ipak nešto širi na račun rastojanja, jer je i ovako odnos između visine i širine preveliki.
Na slici je primer jedne registarske oznake, koja se završava slovima WĆ. Pošto najniža rezolucija u kojoj komercijalni sistemi za čitanje tablica prepoznaju pojedinačnu cifru iznosi 10×20 piksela, na slici je prikazano kako će ih neuronska mreža „videti“ posle skaliranja svakog od pročitanih znakova na tu rezoluciju.
Sami procenite kolika je verovatnoća greške kada se slovo W samo u jednom ili dva piksela razlikuje od M, X ili H, a o slovu Ć da i ne govorimo – neuronska mreža će imati veoma sličan skor za C, Ć i Č, pa će izbor biti praktično nasumičan. Situacija bi mogla donekle da se poboljša dodavanjem posebnih neurona u skrivenom sloju neuronske mreže koji bi obrađivali samo ove mrlje od dijakritika, ali je veliko pitanje koliko će vlasti u ostalim zemljama biti raspoložene da investiraju u dodatni softver kako bi rešavale naše propuste.
Sistemi sa višom rezolucijom, koji se takođe koriste, praviće manje grešaka, ali samo kod savršeno čistih tablica, kakva je ova. Treba reći da bi dobar poznavalac neuronskih mreža lako mogao da zna kako da „slučajno“ zaprlja tablicu tako da ljudskom oku ne bude preterano sumnjivo, a da neuronska mreža veoma verovatno pročita pogrešnu oznaku.
Čekaju li nas problemi?
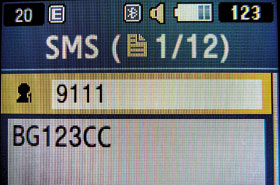 | | Slika 5: Kako uplatiti parking ako registarska oznaka sadrži dijakritike? |
Pomoćnik direktora Zavoda za izradu novčanica, u čijoj nadležnosti su i dokumenta i registarske tablice, zvanično je izjavio: „Font je dizajniran tako da pre svega bude lako mašinski čitljiv od strane raznih kamera koje će se, između ostalog, koristiti i za automatsko registrovanje prekršaja i prosleđivanje kazne na kućnu adresu vlasnika vozila.“ Ne znamo da li je ova izjava važila za stari predlog FE‑Schrift fonta, ali ako se odnosi na ovaj koji je upotrebljen za nove tablice, onda je teško složiti se s njom.
Postoji mnnogo razloga za ovaj zaključak, a najvažniji se tiče dizajna slova sa dijakriticima, jer su oni nesrazmerno mali i teško primetni. Zbog toga možemo da očekujemo jedan od tri moguća pravca razvoja događaja: da se sistem za automatsko registrovanje prekršaja koristi uz bezbroj problema, da se zbog velikog broja grešaka potpuno obustavi instalacija tog sistema, ili da se tablice ponovo menjaju.
Problema će biti i sa vozilima koja prelaze državnu granicu, naročito ako se kreću ka razvijenim zapadnim zemljama. Kada automatizovani sistem u inostranstvu registruje prekršaj, veoma je verovatno da će evidentirati pogrešnu oznaku na tablici. Tako će se pravi prekršilac lako vratiti u Srbiju, ali će njegov „dvojnik“ (kod koga se oznaka razlikuje samo u dijakriticima), ni kriv ni dužan, biti zadržan na granici gde će morati, verovatno bezuspešno, da dokazuje svoju nevinost.
|



















